Persisted Queries
Używaj queries GraphQL do tworzenia wstępnie zdefiniowanych endpointów jak w REST, czerpiąc korzyści z obu podejść.
Opis
Dzięki REST tworzysz wiele endpointów, z których każdy zwraca wstępnie zdefiniowany zestaw danych.
| Zalety | Wady |
|---|---|
| ✅ Jest proste | ❌ Tworzenie wszystkich endpointów jest żmudne |
✅ Dostępne przez GET lub POST | ❌ Projekt może napotykać wąskie gardła czekając na gotowość endpointów |
| ✅ Może być przechowywane w pamięci podręcznej serwera lub CDN | ❌ Tworzenie dokumentacji jest obowiązkowe |
| ✅ Jest bezpieczne: ujawniane są tylko zamierzone dane | ❌ Może być wolne (głównie dla aplikacji mobilnych), ponieważ aplikacja może potrzebować wielu żądań, aby pobrać wszystkie dane |
Dzięki GraphQL wysyłasz dowolną query do jednego endpointu, który zwraca dokładnie żądane dane.
| Zalety | Wady |
|---|---|
| ✅ Brak nadmiarowego lub niepełnego pobierania danych | ❌ Dostępne tylko przez POST |
| ✅ Może być szybkie, ponieważ wszystkie dane są pobierane w jednym żądaniu | ❌ Nie może być przechowywane w pamięci podręcznej serwera lub CDN, przez co jest wolniejsze i droższe niż mogłoby być |
| ✅ Umożliwia szybką iterację projektu | ❌ Może wymagać wynajdowania koła na nowo, np. przy przesyłaniu plików lub obsłudze pamięci podręcznej |
| ✅ Może być samo-dokumentujące | ❌ Wymaga radzenia sobie z dodatkowymi złożonościami, takimi jak problem N+1 |
| ✅ Udostępnia edytor queries (GraphiQL), który upraszcza zadanie |
Persisted queries łączą oba te podejścia:
- Używają GraphQL do tworzenia i rozwiązywania queries
- Ale zamiast udostępniać jeden endpoint, udostępniają każdą wstępnie zdefiniowaną query pod własnym endpointem
Dzięki temu otrzymujemy wiele endpointów z predefiniowanymi danymi, jak w REST, ale tworzone przy użyciu GraphQL, czerpiąc zalety z obu i unikając ich wad:
| Zalety | Wady |
|---|---|
✅ Dostępne przez GET lub POST | |
| ✅ Może być przechowywane w pamięci podręcznej serwera lub CDN | |
| ✅ Jest bezpieczne: ujawniane są tylko zamierzone dane | |
| ✅ Brak nadmiarowego lub niepełnego pobierania danych | |
| ✅ Może być szybkie, ponieważ wszystkie dane są pobierane w jednym żądaniu | POST |
| ✅ Umożliwia szybką iterację projektu | |
| ✅ Może być samo-dokumentujące | |
| ✅ Udostępnia edytor queries (GraphiQL), który upraszcza zadanie |

Wykonywanie Persisted Query
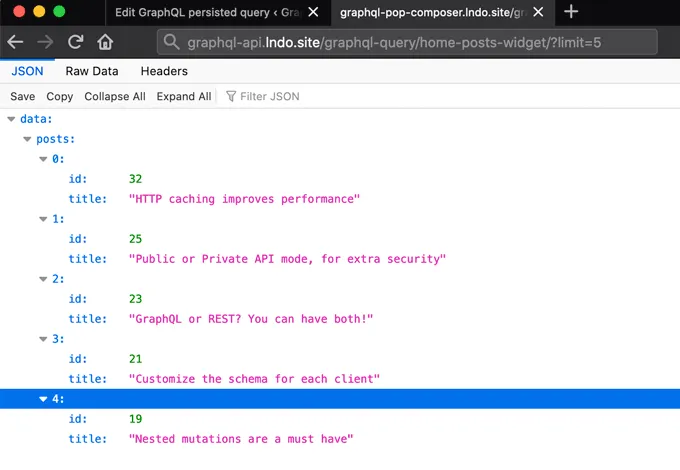
Po opublikowaniu persisted query możemy ją wykonać za pomocą jej permalinku.
Persisted query może być wykonana bezpośrednio w przeglądarce, ponieważ jest dostępna przez GET, a my otrzymamy żądane dane w formacie JSON:
Tworzenie Persisted Query
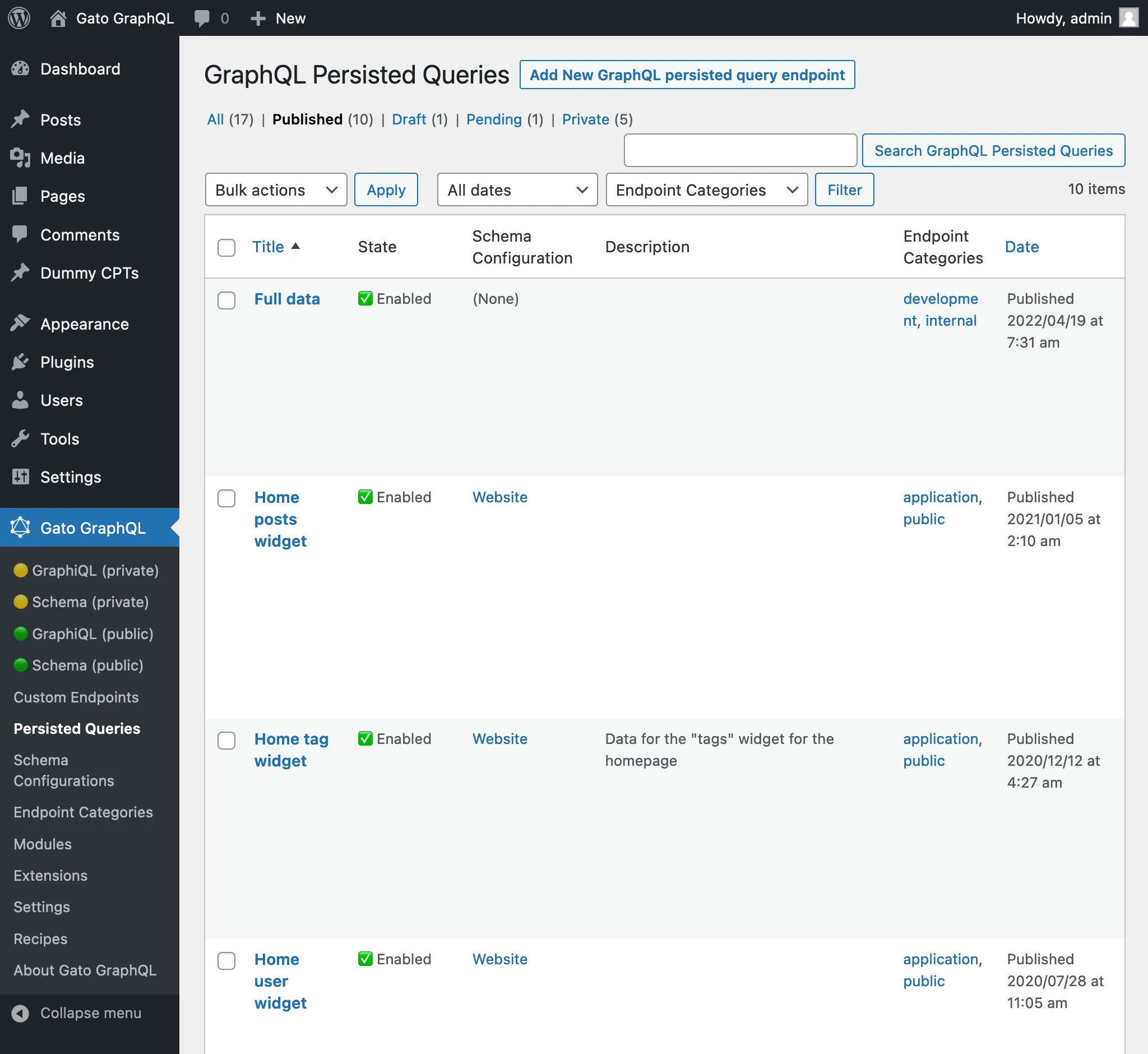
Kliknięcie linku Persisted Queries w menu wyświetla listę wszystkich utworzonych persisted queries:
Persisted query to niestandardowy typ wpisu (CPT). Aby utworzyć nową persisted query, kliknij przycisk "Add New GraphQL persisted query", który otworzy edytor WordPress:
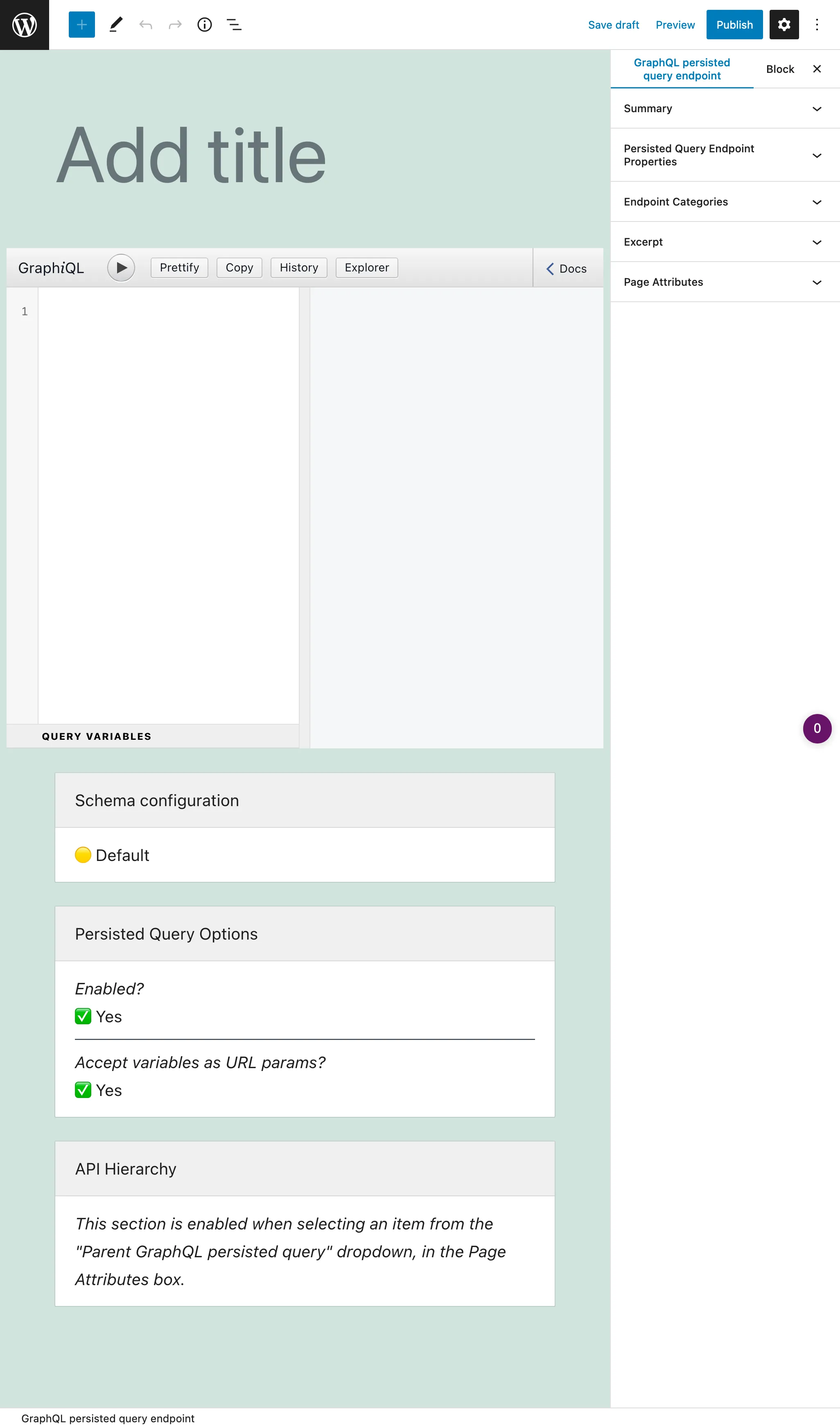
Głównym elementem wejściowym jest klient GraphiQL, który domyślnie zawiera Explorer. Kliknięcie pól na lewym panelu bocznym dodaje je do query, a kliknięcie przycisku "Run" wykonuje query:

Gdy query jest gotowa, opublikuj ją, a jej permalink staje się jej endpointem. Link do endpointu (oraz do źródła) jest wyświetlany w panelu bocznym "Persisted Query Endpoint Overview":
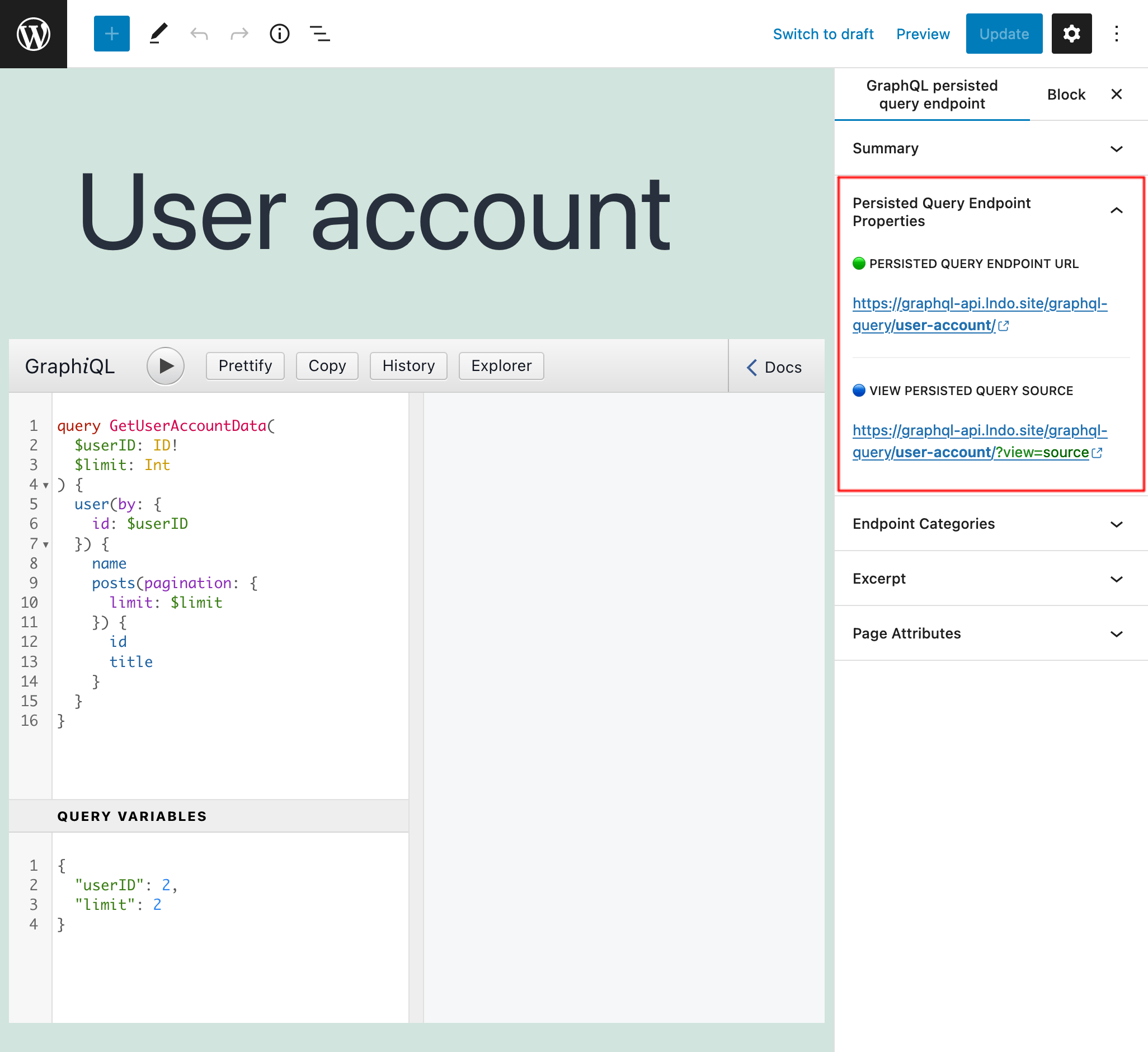
Dodanie ?view=source do permalinku spowoduje wyświetlenie persisted query i jej konfiguracji (pod warunkiem, że użytkownik jest zalogowany i jego rola ma do niej dostęp):

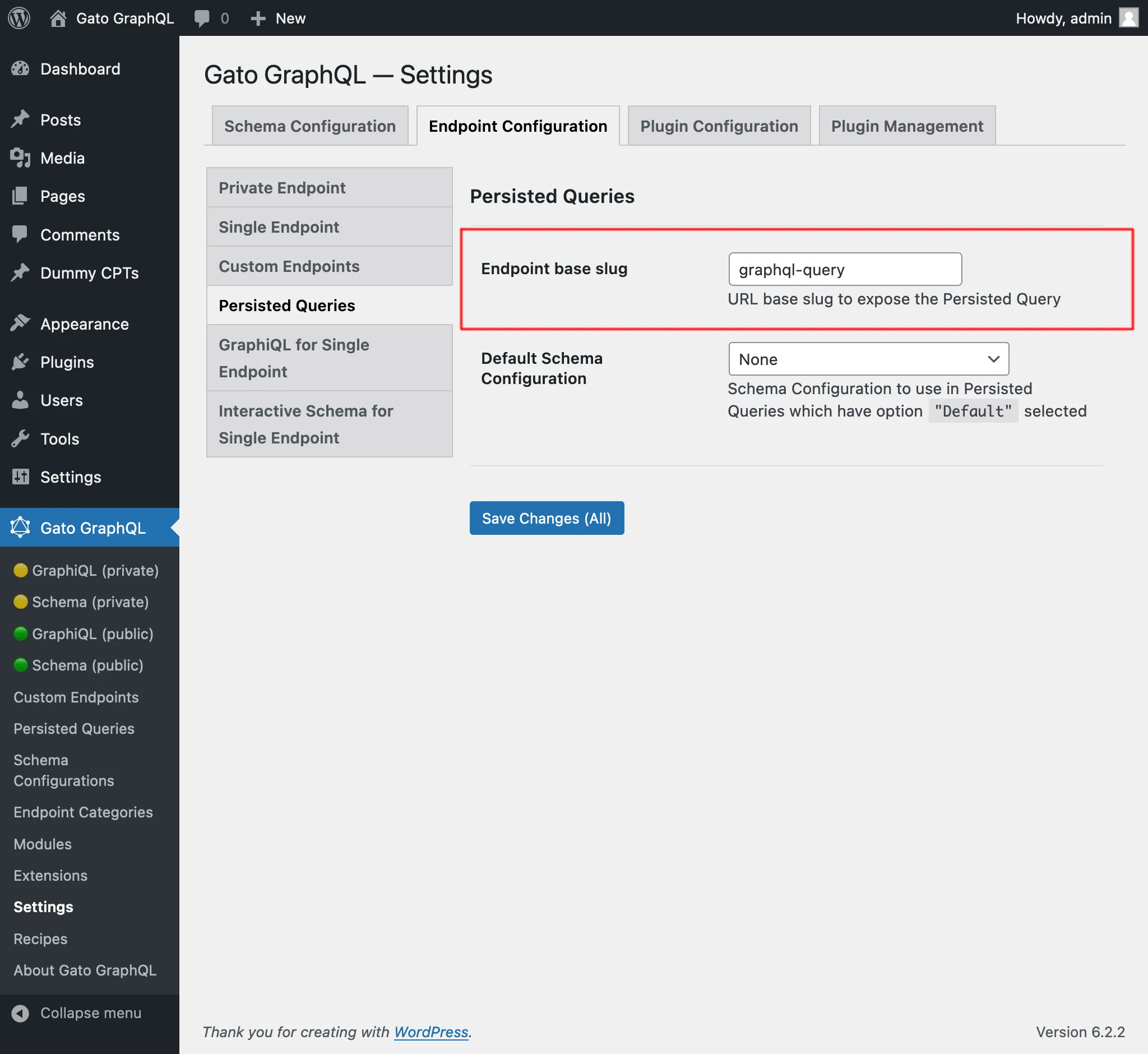
Domyślnie endpoint persisted query ma ścieżkę /graphql-query/, a wartość ta jest konfigurowalna w Ustawieniach:
Konfiguracja schematu
Określenie, jakie elementy zawiera schemat oraz jaki dostęp będą mieli do niego użytkownicy, jest definiowane w konfiguracji schematu.
Dlatego musimy utworzyć konfigurację schematu, a następnie wybrać ją z listy rozwijanej:

Organizowanie Persisted Queries według kategorii
W panelu bocznym "Endpoint categories" możemy dodawać kategorie, które pomagają zarządzać Persisted Query:
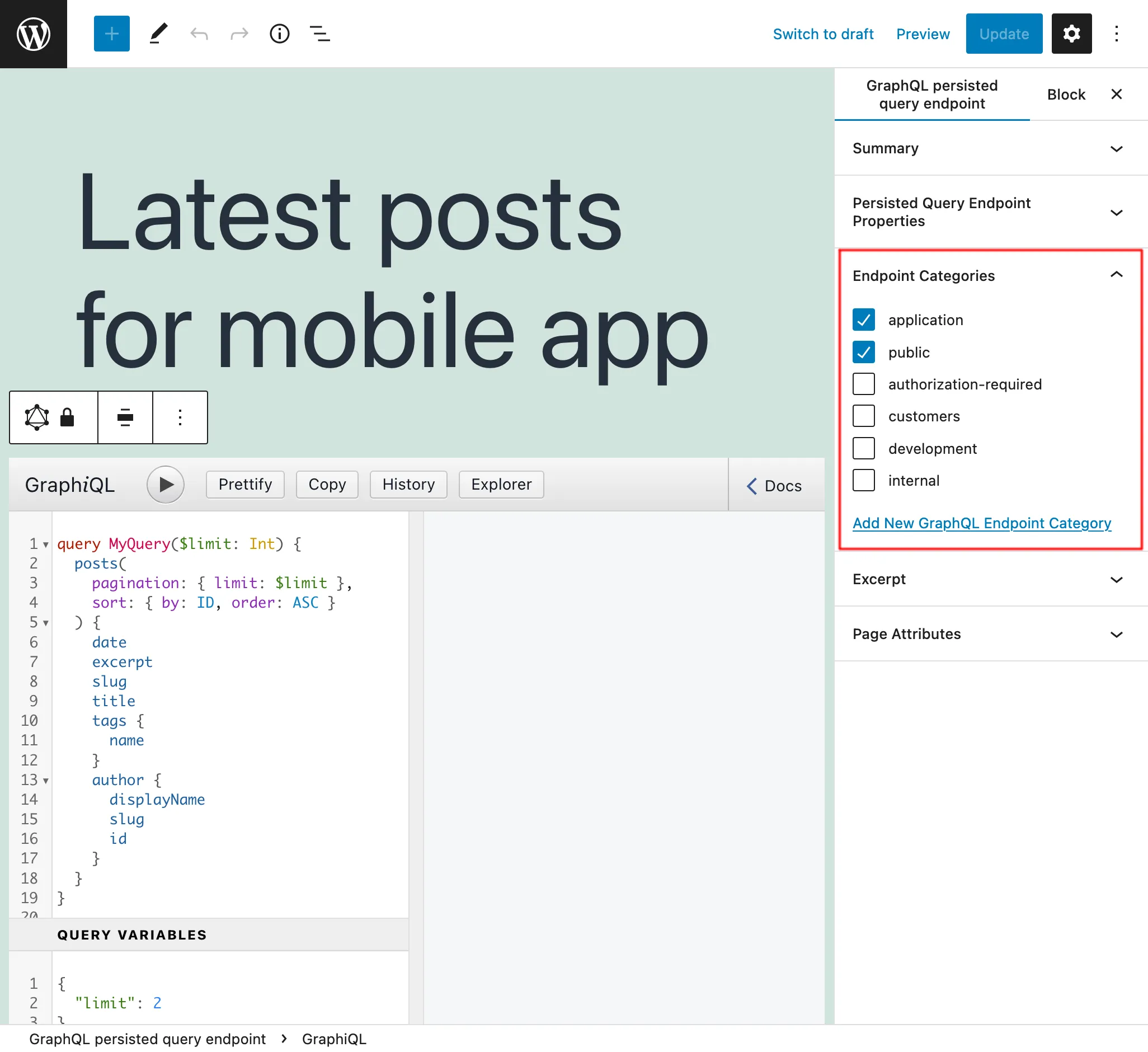
Na przykład możemy tworzyć kategorie do zarządzania endpointami według klienta, aplikacji lub dowolnej innej wymaganej informacji:

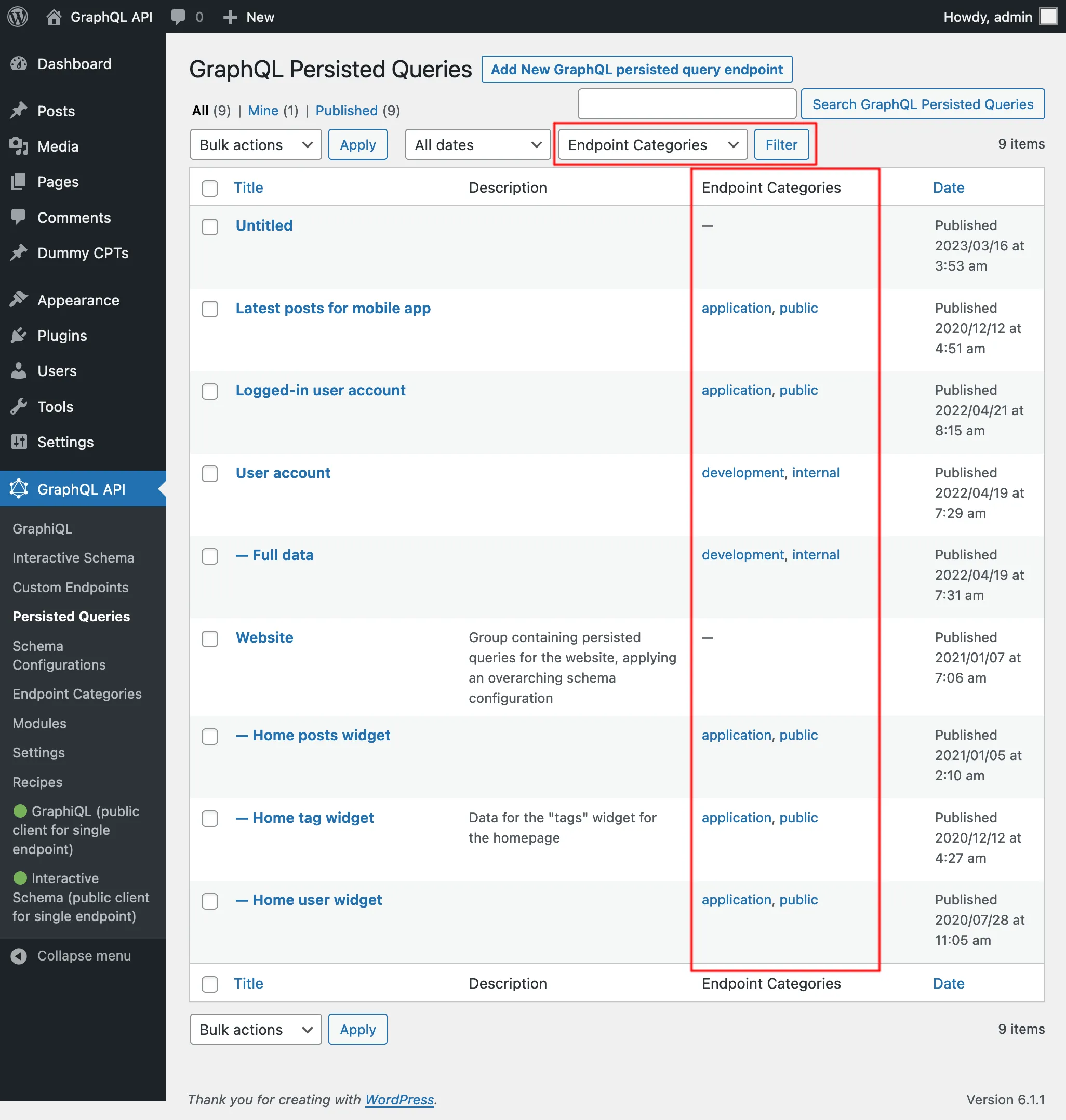
Na liście Persisted Queries możemy przeglądać ich kategorie, a kliknięcie dowolnego linku kategorii lub użycie filtra na górze spowoduje wyświetlenie tylko wpisów należących do tej kategorii:
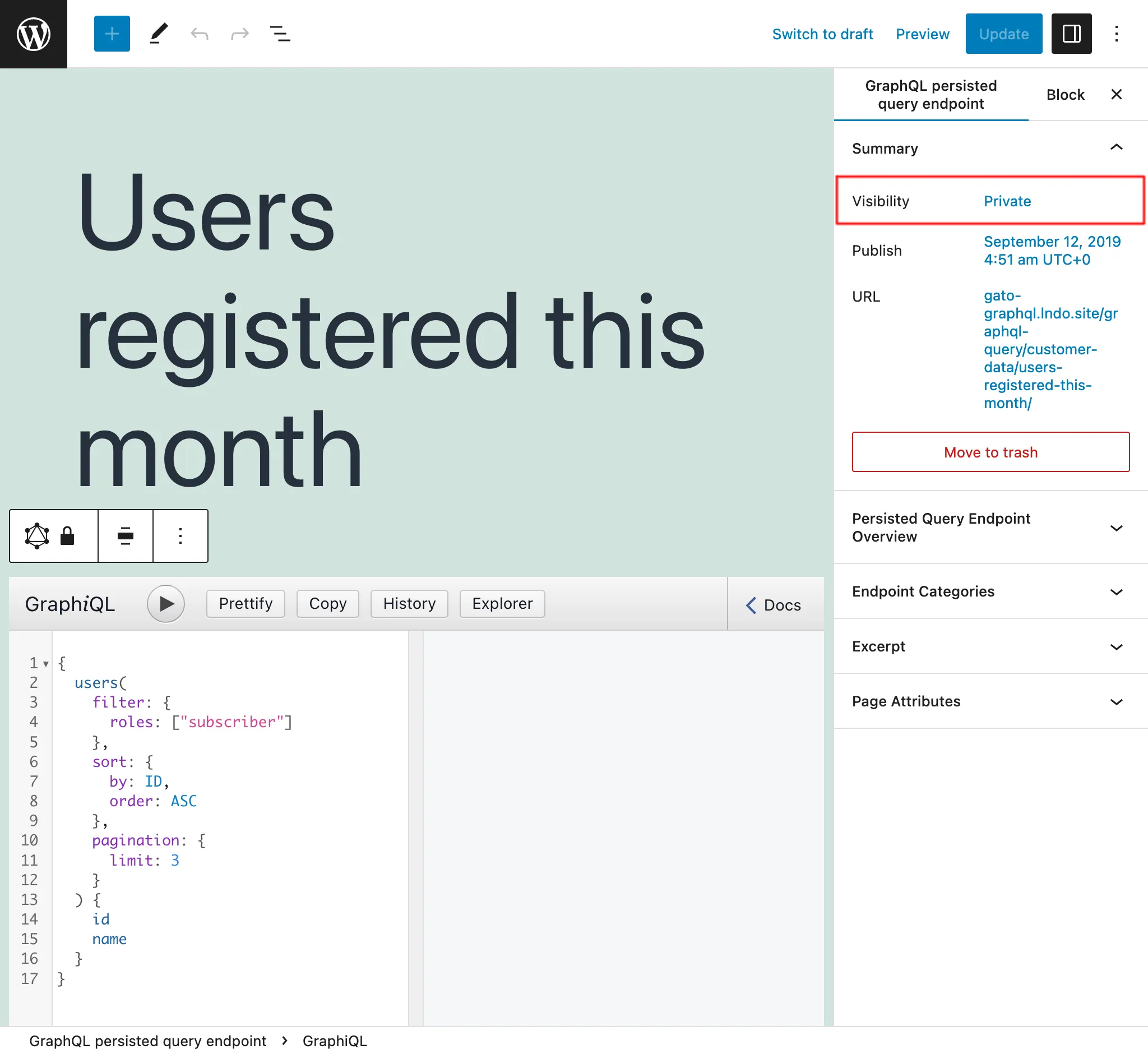
Prywatne persisted queries
Ustawiając status Persisted Query jako private, endpoint będzie dostępny tylko dla administratora. Zapobiega to niezamierzonemu udostępnianiu naszych danych użytkownikom, którzy nie powinni mieć do nich dostępu.
Na przykład możemy tworzyć prywatne Persisted Queries, które pomagają zarządzać aplikacją, np. pobierając dane do tworzenia raportów z naszymi metrykami.
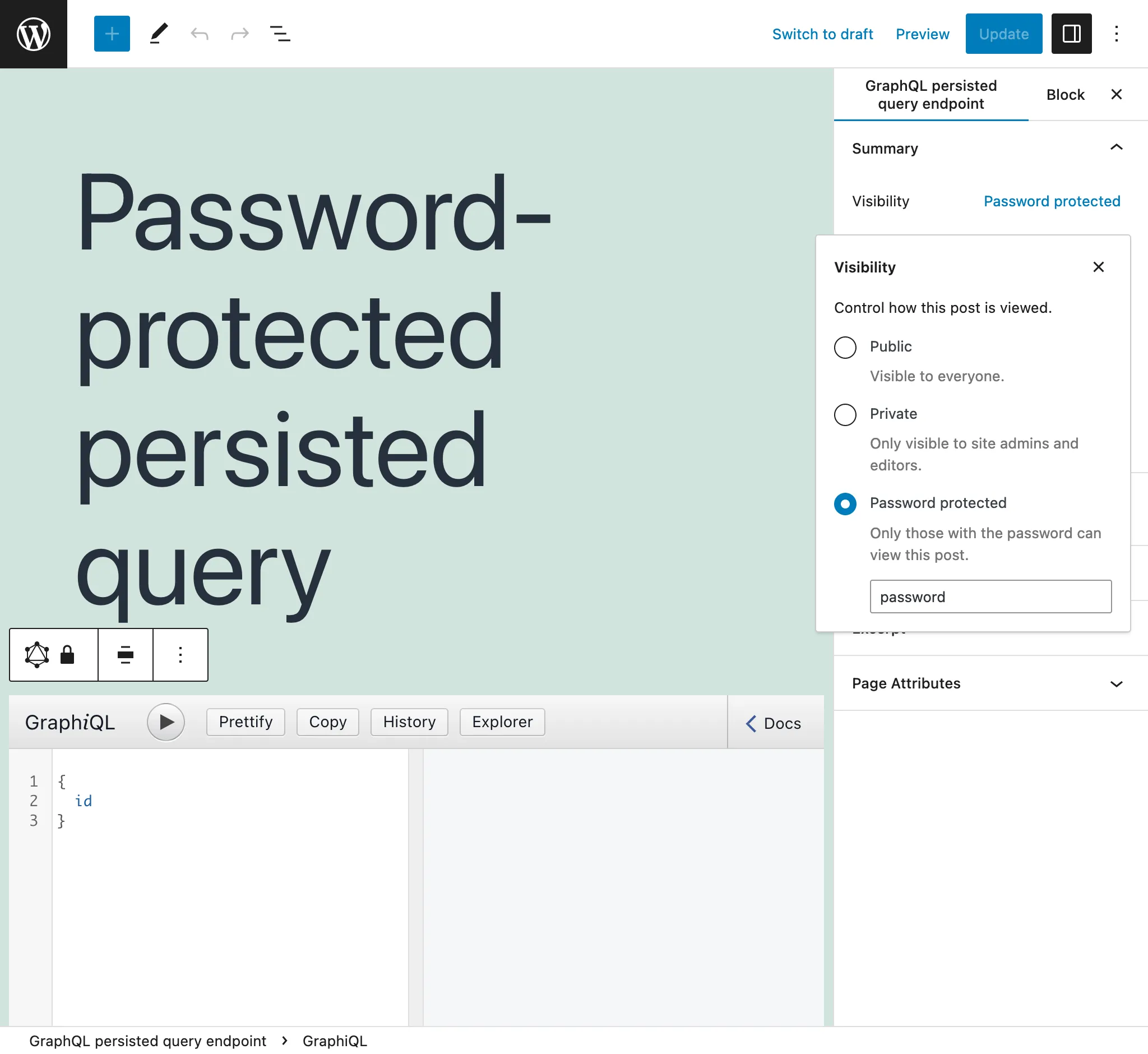
Persisted queries chronione hasłem
Jeśli tworzymy Persisted Query dla konkretnego klienta, możemy przypisać do niej hasło, aby zapewnić dodatkowy poziom bezpieczeństwa i zagwarantować, że tylko ten klient uzyska dostęp do endpointu.
Przy pierwszym dostępie do persisted query chronionej hasłem napotykamy ekran z prośbą o podanie hasła:
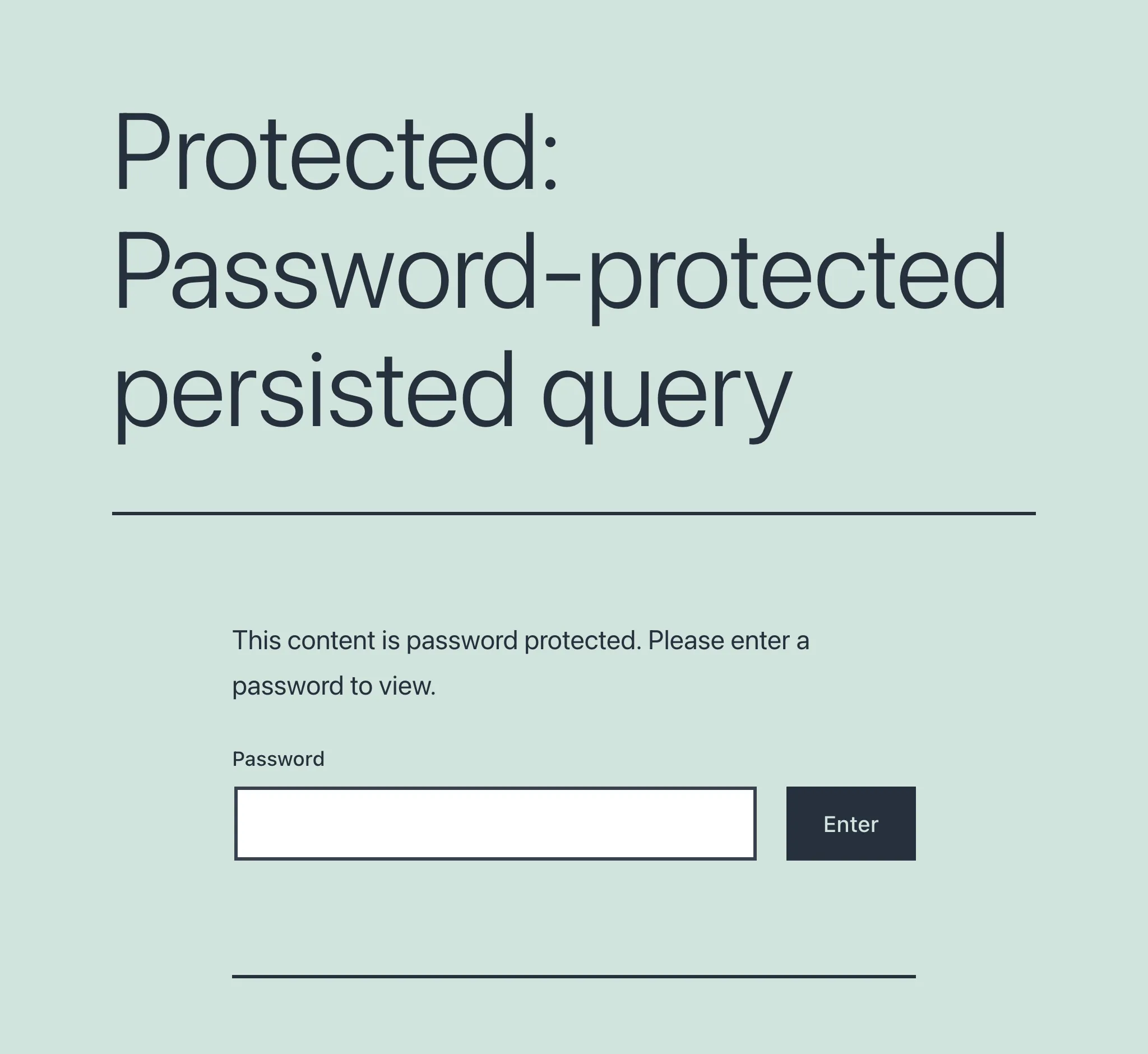
Dopiero po podaniu i zweryfikowaniu hasła użytkownik uzyska dostęp do zamierzonego endpointu.
Dynamiczne persisted queries za pomocą parametrów URL
Wartość każdej zmiennej może być ustawiona za pomocą parametru URL (o nazwie zmiennej) podczas wykonywania persisted query. Jeśli opcja "Czy parametry URL zastępują zmienne?" jest włączona, parametr URL ma pierwszeństwo. W przeciwnym razie pierwszeństwo ma wartość zdefiniowana w słowniku zmiennych (jeśli istnieje).
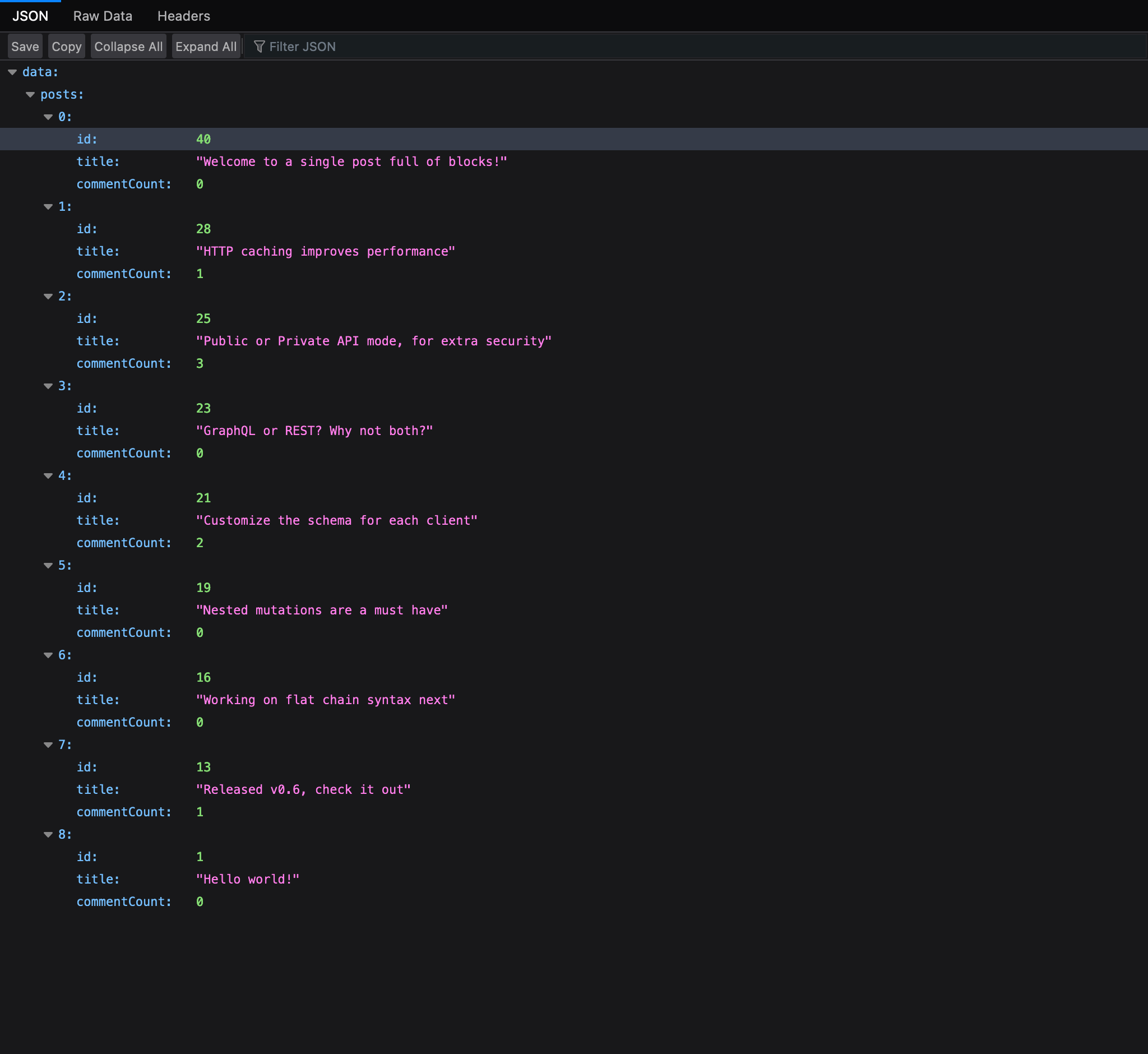
Na przykład w tej query liczba wyników jest kontrolowana przez zmienną $limit, z domyślną wartością 3:
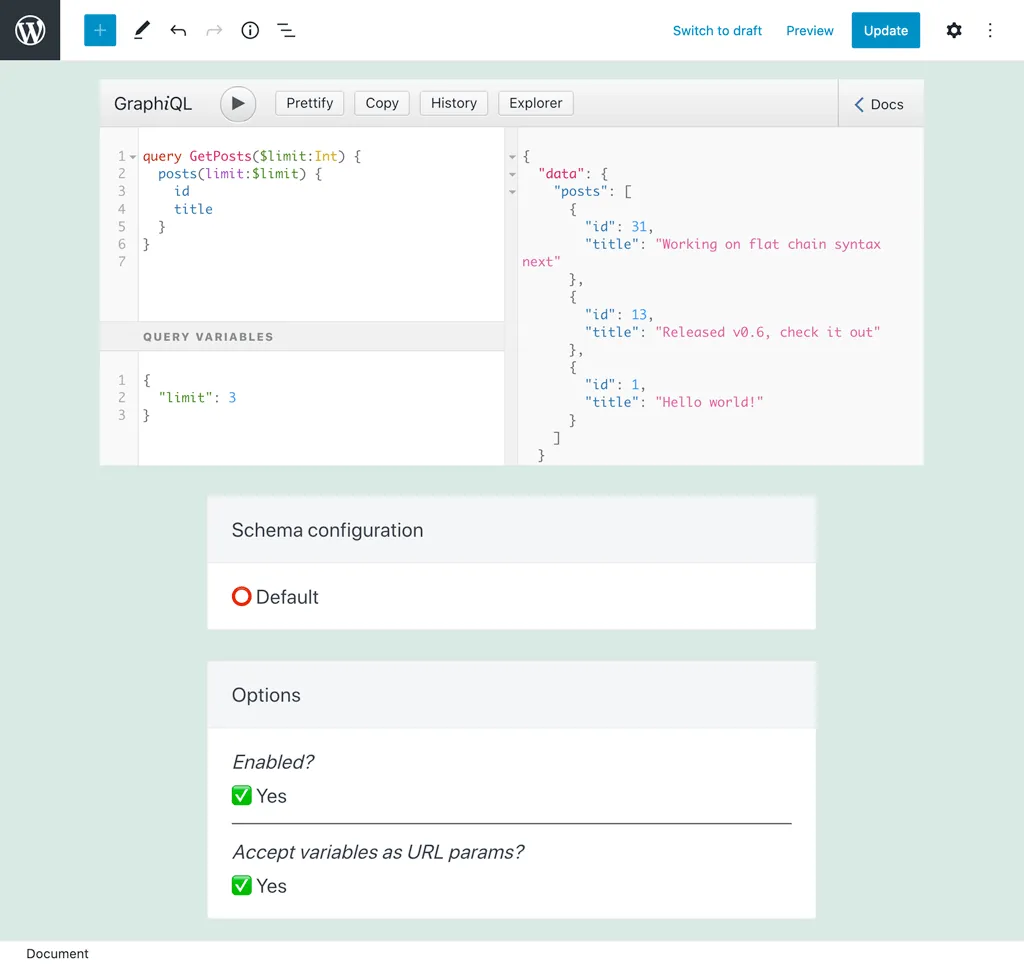
Wykonując tę persisted query i przekazując ?limit=5, query zostanie wykonana zwracając 5 wyników: