
Silnik ładowania danych
Gato GraphQL używa komponentów po stronie serwera do reprezentowania modelu danych (nie grafów ani drzew). Przyjrzyjmy się, jak wykonuje proces ładowania danych w celu rozwiązania query GraphQL.
Aby przetworzyć dane, musimy spłaszczyć komponenty do typów (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), uporządkować je zgodnie z kolejnością pojawiania się w hierarchii komponentów (Director, następnie Film, następnie Actor) i obsługiwać je w "iteracjach", pobierając dane obiektów dla każdego typu w jego własnej iteracji, w ten sposób:

Silnik ładowania danych serwera musi zaimplementować następujący (pseudo-)algorytm do ładowania danych:
Przygotowanie:
- Przygotować pustą kolejkę do przechowywania listy identyfikatorów obiektów, które muszą zostać pobrane z bazy danych, zorganizowanych według typu (każdy wpis będzie miał postać:
[type => lista identyfikatorów]) - Pobrać identyfikator obiektu wyróżnionego reżysera i umieścić go w kolejce pod typem
Director
Pętla aż do wyczerpania wpisów w kolejce:
- Pobrać pierwszy wpis z kolejki: typ i listę identyfikatorów (np.:
Directori[2]), a następnie usunąć ten wpis z kolejki - Używając obiektu
TypeDataLoaderdanego typu, wykonać jedno zapytanie do bazy danych w celu pobrania wszystkich obiektów dla tego typu z podanymi identyfikatorami - Jeśli typ posiada pola relacyjne (np.: typ
Directorposiada pole relacyjnefilmstypuFilm), zebrać wszystkie identyfikatory z tych pól ze wszystkich obiektów pobranych w bieżącej iteracji (np.: wszystkie identyfikatory z polafilmsze wszystkich obiektów typuDirector) i umieścić te identyfikatory w kolejce pod odpowiednim typem (np.: identyfikatory[3, 8]pod typemFilm).
Po zakończeniu iteracji załadujemy wszystkie dane obiektów dla wszystkich typów, w ten sposób:
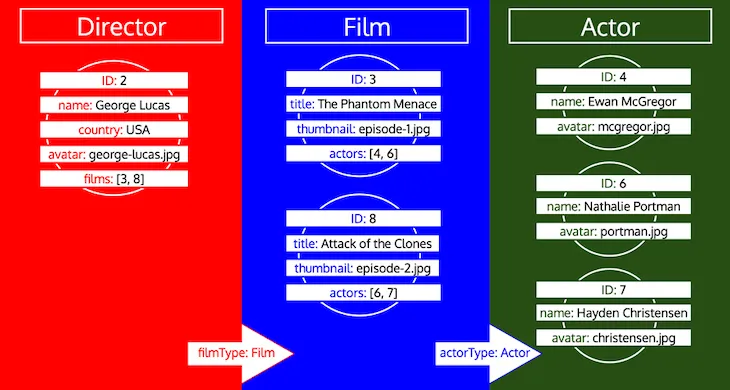
Zwróć uwagę, jak wszystkie identyfikatory dla danego typu są zbierane, dopóki typ nie zostanie przetworzony w kolejce. Jeśli na przykład dodamy pole relacyjne preferredActors do typu Director, te identyfikatory zostaną dodane do kolejki pod typem Actor i zostaną przetworzone razem z identyfikatorami z pola actors typu Film:
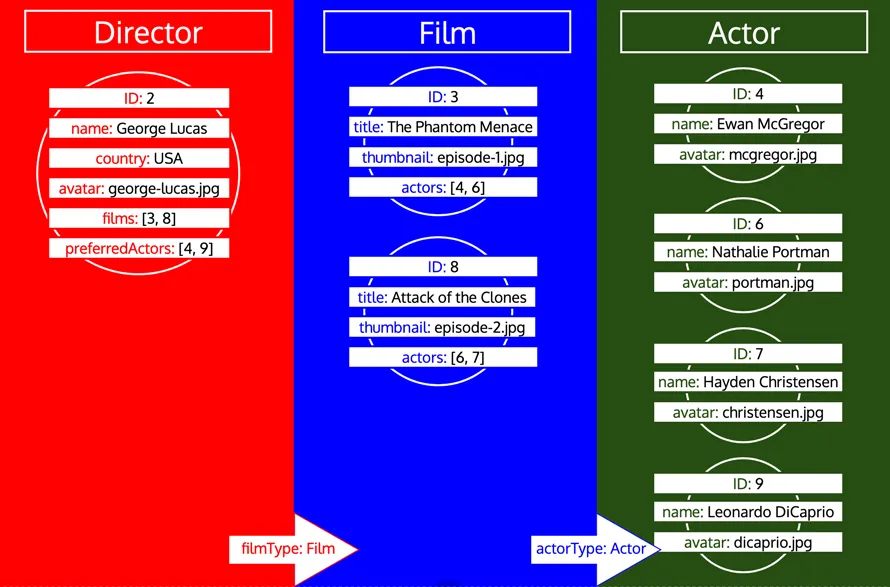
Jeśli jednak typ został już przetworzony i następnie musimy załadować więcej danych z tego typu, jest to nowa iteracja na tym typie. Na przykład dodanie pola relacyjnego preferredDirector do typu Author spowoduje ponowne dodanie typu Director do kolejki:
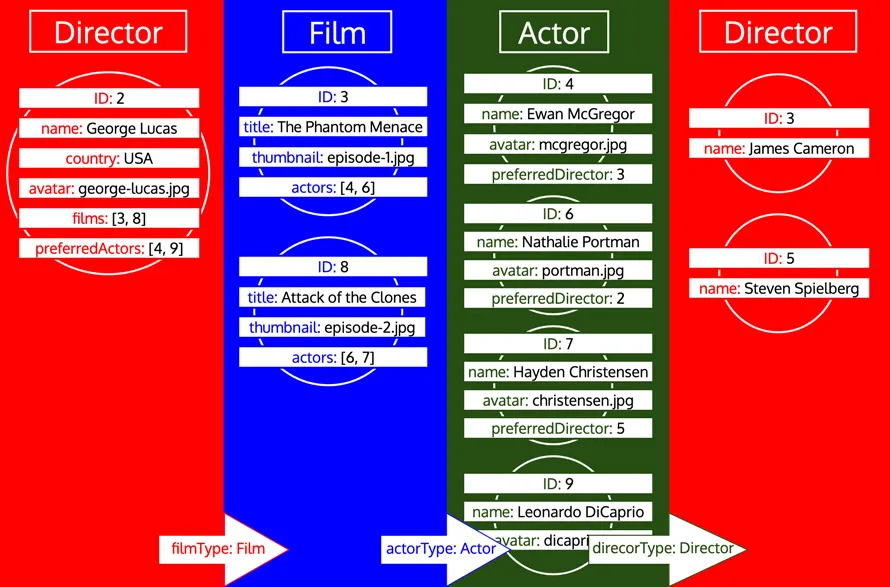
Teraz, gdy pobraliśmy wszystkie dane obiektów, musimy nadać im kształt oczekiwanej odpowiedzi, odzwierciedlając query GraphQL. Jednak, jak widać, dane nie mają wymaganej struktury drzewa. Zamiast tego pola relacyjne zawierają identyfikatory zagnieżdżonego obiektu, naśladując sposób reprezentacji danych w relacyjnej bazie danych. Dlatego, korzystając z tego porównania, dane pobrane dla każdego typu mogą być przedstawione jako tabela, w ten sposób:
Tabela dla typu Director:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Tabela dla typu Film:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Tabela dla typu Actor:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Mając wszystkie dane zorganizowane w tabelach i wiedząc, jak każdy typ odnosi się do innych (tj. Director odwołuje się do Film przez pole films, Film odwołuje się do Actor przez pole actors), serwer GraphQL może łatwo przekonwertować dane do oczekiwanego kształtu drzewa:
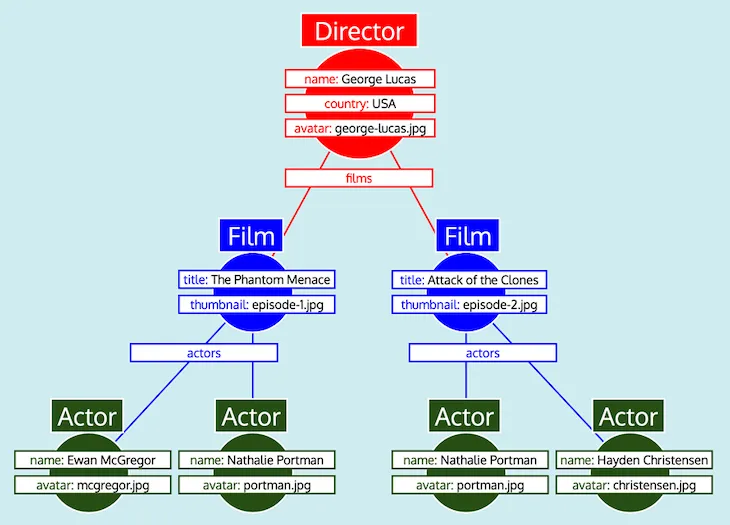
Na koniec serwer GraphQL zwraca drzewo, które ma kształt oczekiwanej odpowiedzi:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}Analiza złożoności czasowej rozwiązania
Przeanalizujmy notację dużego O algorytmu ładowania danych, aby zrozumieć, jak liczba zapytań wykonywanych do bazy danych rośnie wraz ze wzrostem liczby danych wejściowych, upewniając się, że to rozwiązanie jest wydajne.
Silnik ładowania danych ładuje dane w iteracjach odpowiadających każdemu typowi. W momencie rozpoczęcia iteracji będzie już posiadał listę wszystkich identyfikatorów wszystkich obiektów do pobrania, a zatem może wykonać jedno zapytanie w celu pobrania wszystkich danych dla odpowiednich obiektów. Z tego wynika, że liczba zapytań do bazy danych będzie rosła liniowo wraz z liczbą typów zaangażowanych w query. Innymi słowy, złożoność czasowa wynosi O(n), gdzie n jest liczbą typów w query (jednak jeśli typ jest iterowany więcej niż raz, musi być dodany więcej niż raz do n).
To rozwiązanie jest bardzo wydajne, znacznie lepsze niż wykładnicza złożoność oczekiwana przy obsłudze grafów lub logarytmiczna złożoność oczekiwana przy obsłudze drzew.
Zaimplementowany kod PHP
Proces ładowania danych odbywa się w funkcji getComponentData klasy Engine w pakiecie Component Model.