
Pipeline dyrektyw
Dyrektywy są umieszczane w potoku i wykonywane w kolejności. Ich pierwotny projekt jest prosty, wygląda tak:

W tej architekturze:
- Wejściem do potoku jest wartość pola dostarczona przez resolver pola
- Każda dyrektywa wykonuje swoją logikę i przekazuje wynik do następnej dyrektywy w potoku
- Wyjściem potoku będzie rozwiązana wartość pola, przetworzona przez wszystkie dyrektywy
Ta architektura jednak nie wykorzystuje w pełni możliwości GraphQL. Poniżej znajduje się opis wszystkich etapów rzeczywistego potoku dyrektyw, aż do osiągnięcia faktycznego projektu zaimplementowanego w Gato GraphQL.
Dyrektywy jako bloki budulcowe rozwiązywania query
Początkowo moglibyśmy rozważyć, aby serwer GraphQL rozwiązywał pole za pomocą jakiegoś mechanizmu, a następnie przekazywał tę wartość jako wejście do potoku dyrektyw.
Jednak znacznie prostsze jest posiadanie jednego mechanizmu do obsługi wszystkiego: wywoływanie resolverów pola (zarówno do walidacji pól, jak i ich rozwiązywania) może już odbywać się za pośrednictwem potoku dyrektyw. W tym przypadku potok dyrektyw jest jedynym mechanizmem używanym do rozwiązywania query.
Z tego powodu serwer Gato GraphQL jest wyposażony w dwie specjalne dyrektywy:
@validatewywołuje resolver pola w celu sprawdzenia, czy pole może zostać rozwiązane (np.: składnia jest poprawna, pole istnieje itp.)- W przypadku powodzenia,
@resolveValueAndMergewywołuje resolver pola w celu rozwiązania pola i scala wartość z obiektem odpowiedzi
Te dwie dyrektywy są specjalnego typu „systemowego": są zarezerwowane wyłącznie dla silnika GraphQL i są niejawne dla każdego pola. (W przeciwieństwie do nich, standardowe dyrektywy są jawne: są dodawane do query przez użytkownika.)
Używając tych dwóch dyrektyw, ta query:
query {
field1
field2 @directiveA
}...zostanie rozwiązana jako ta:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}Potok wygląda teraz tak (należy zauważyć, że potok otrzymuje pole jako wejście, a nie jego pierwotną rozwiązaną wartość):

Sloty potoku
Dyrektywy są normalnie wykonywane po @resolveValueAndMerge, ponieważ najczęściej wiążą się z aktualizacją wartości rozwiązanego pola. Jednak istnieją inne dyrektywy, które muszą być wykonane przed @validate lub pomiędzy @validate a @resolveValueAndMerge.
Na przykład:
- Aby zmierzyć czas potrzebny do rozwiązania pola, dyrektywa
@traceExecutionTimemoże uzyskać bieżący czas przed i po rozwiązaniu pola, umieszczając subdyrektywy@startTracingExecutionTimena początku i@endTracingExecutionTimena końcu potoku - Dyrektywa
@cachemusi sprawdzić, czy żądane pole jest w pamięci podręcznej i zwrócić tę odpowiedź bezpośrednio, przed wykonaniem@resolveValueAndMerge
Potok będzie oferował pięć różnych slotów za pomocą klasy PipelinePositions, a dyrektywa wskaże, w którym z nich ma być wykonana:
- Slot
"beginning": na samym początku - Slot
"before-validate": przed przeprowadzeniem walidacji - Slot
"middle": po walidacji i przed rozwiązaniem pola - Slot
"after-resolve": po rozwiązaniu pola - Slot
"end": na samym końcu
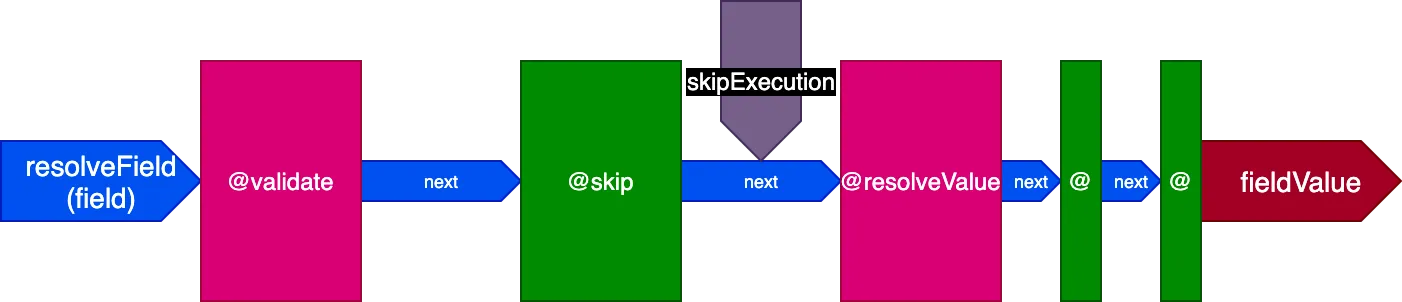
Potok dyrektyw wygląda teraz tak (biorąc pod uwagę tylko 3 etapy, dla uproszczenia):

Należy zauważyć, jak dyrektywy @skip i @include mogą być tak łatwo obsługiwane w tej architekturze: umieszczone w slocie "middle", mogą poinformować dyrektywę @resolveValueAndMerge (wraz ze wszystkimi dyrektywami na późniejszych etapach potoku), aby nie wykonywała się, ustawiając flagę skipExecution na true.
Wykonywanie dyrektywy na wielu polach w jednym wywołaniu
Do tej pory rozważaliśmy jedno pole jako wejście do potoku dyrektyw. Jednak w typowej query GraphQL otrzymamy kilka pól, na których należy wykonać dyrektywy.
Na przykład w poniższej query dyrektywa @upperCase jest wykonywana na polach "field1" i "field2":
query {
field1 @upperCase
field2 @upperCase
field3
}Ponadto, ponieważ silnik GraphQL dodaje systemowe dyrektywy @validate i @resolveValueAndMerge do każdego pola w query, tak że ta query:
query {
field1
field2
field3
}...jest rozwiązywana jako ta query:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Zatem dyrektywy systemowe zawsze będą otrzymywać wszystkie pola jako wejścia.
W konsekwencji potok dyrektyw jest zaprojektowany tak, aby otrzymywać wiele pól jako wejście, a nie tylko jedno na raz:

Ta architektura jest bardziej wydajna, ponieważ wykonanie dyrektywy tylko raz dla wszystkich pól jest szybsze niż wykonywanie jej raz na pole, a wyniki będą takie same.
Na przykład podczas walidacji, czy użytkownik jest zalogowany w celu przyznania dostępu do schematu, operacja może być wykonana tylko raz. Uruchomienie następującego kodu:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}jest bardziej wydajne niż uruchamianie tego kodu:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}Może się to nie wydawać wielką sprawą podczas wywoływania funkcji lokalnej, takiej jak isUserLoggedIn, jednak może mieć duże znaczenie podczas interakcji z usługami zewnętrznymi, np. przy rozwiązywaniu endpointów REST za pośrednictwem GraphQL. W takich przypadkach wykonanie funkcji raz zamiast wielokrotnie może decydować o tym, czy możliwe jest dostarczenie określonej funkcjonalności.
Zobaczmy przykład. Podczas interakcji z Google Translate za pośrednictwem dyrektywy @translate, API GraphQL musi nawiązać połączenie przez sieć. Wykonanie tego kodu będzie więc tak szybkie, jak to możliwe:
googleTranslateFields([$field1, $field2, $field3]);W przeciwieństwie do tego, wykonywanie funkcji oddzielnie, wielokrotnie, spowoduje większe opóźnienie, co przełoży się na dłuższy czas odpowiedzi i obniży wydajność API. Możliwe, że nie jest to duża różnica przy tłumaczeniu 3 ciągów znaków (gdzie pole jest ciągiem do przetłumaczenia), ale dla 100 lub więcej ciągów z pewnością będzie miało znaczenie:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);Ponadto wykonanie funkcji raz z wszystkimi wejściami może dać lepszą odpowiedź niż wykonywanie funkcji na każdym polu niezależnie. Używając ponownie Google Translate jako przykładu, tłumaczenie będzie dokładniejsze, im więcej danych dostarczymy usłudze.
Na przykład podczas wykonywania poniższego kodu:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");Przy pierwszym niezależnym wykonaniu Google nie zna kontekstu słowa "fork", więc może odpowiedzieć z fork jako sztućcem do jedzenia, jako rozwidleniem drogi lub z innym znaczeniem. Jednak jeśli zamiast tego wykonamy:
googleTranslate(["fork", "road", "sign"]);Na podstawie tej szerszej ilości informacji Google może wywnioskować, że "fork" odnosi się do rozwidlenia drogi i zwrócić precyzyjne tłumaczenie.
Z tych powodów dyrektywy w potoku otrzymują pola wejściowe wszystkie razem, a następnie każda dyrektywa może zdecydować o najlepszym sposobie uruchomienia swojej logiki na tych wejściach (jedno wykonanie na wejście, jedno wykonanie obejmujące wszystkie wejścia lub cokolwiek pomiędzy).
Potok wygląda teraz tak:
Wykonywanie jednego potoku dyrektyw dla całej query
Właśnie dowiedzieliśmy się, że sensowne jest wykonywanie wielu pól na dyrektywę, jednak działa to dobrze, dopóki wszystkie pola mają te same dyrektywy zastosowane do nich. Gdy dyrektywy są różne, może to prowadzić do większej złożoności, która utrudnia implementację i zmniejsza niektóre z uzyskanych korzyści.
Zobaczmy, jak to się dzieje. Rozważmy następującą query:
query {
field1 @directiveA
field2
field3
}Ta dyrektywa jest równoważna tej:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}W tym scenariuszu pola field2 i field3 mają ten sam zestaw dyrektyw, a field1 ma inny, więc musielibyśmy wygenerować 2 różne potoki, aby rozwiązać query:
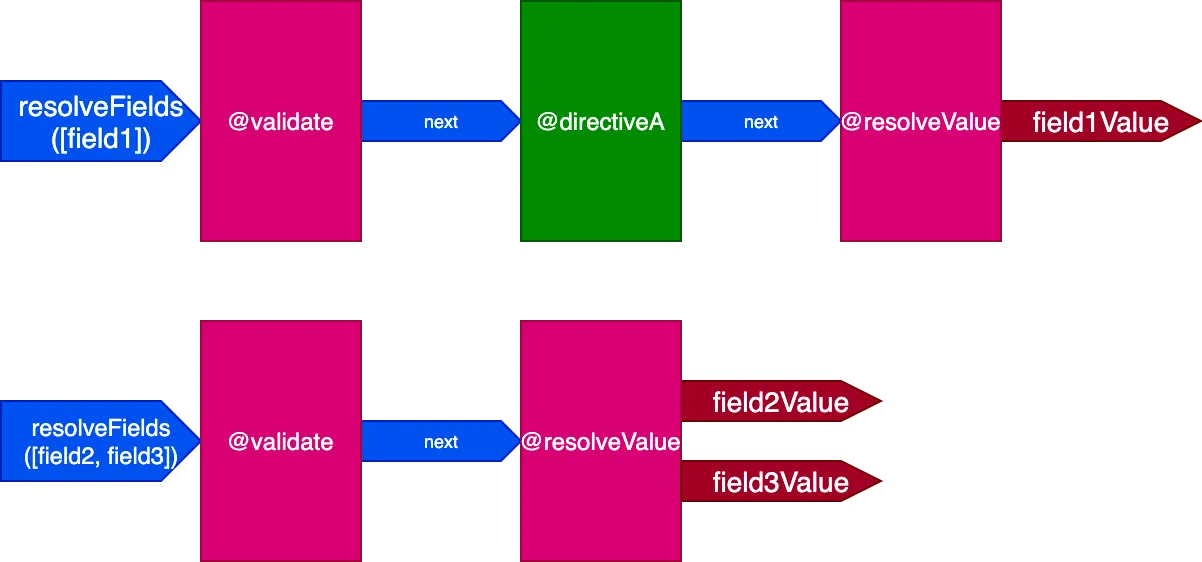
A gdy wszystkie pola mają unikalny zestaw dyrektyw, efekt jest jeszcze bardziej wyraźny. Rozważmy tę query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}Która jest równoważna tej:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}W tej sytuacji będziemy mieć 3 potoki do obsługi 3 pól, tak jak to:
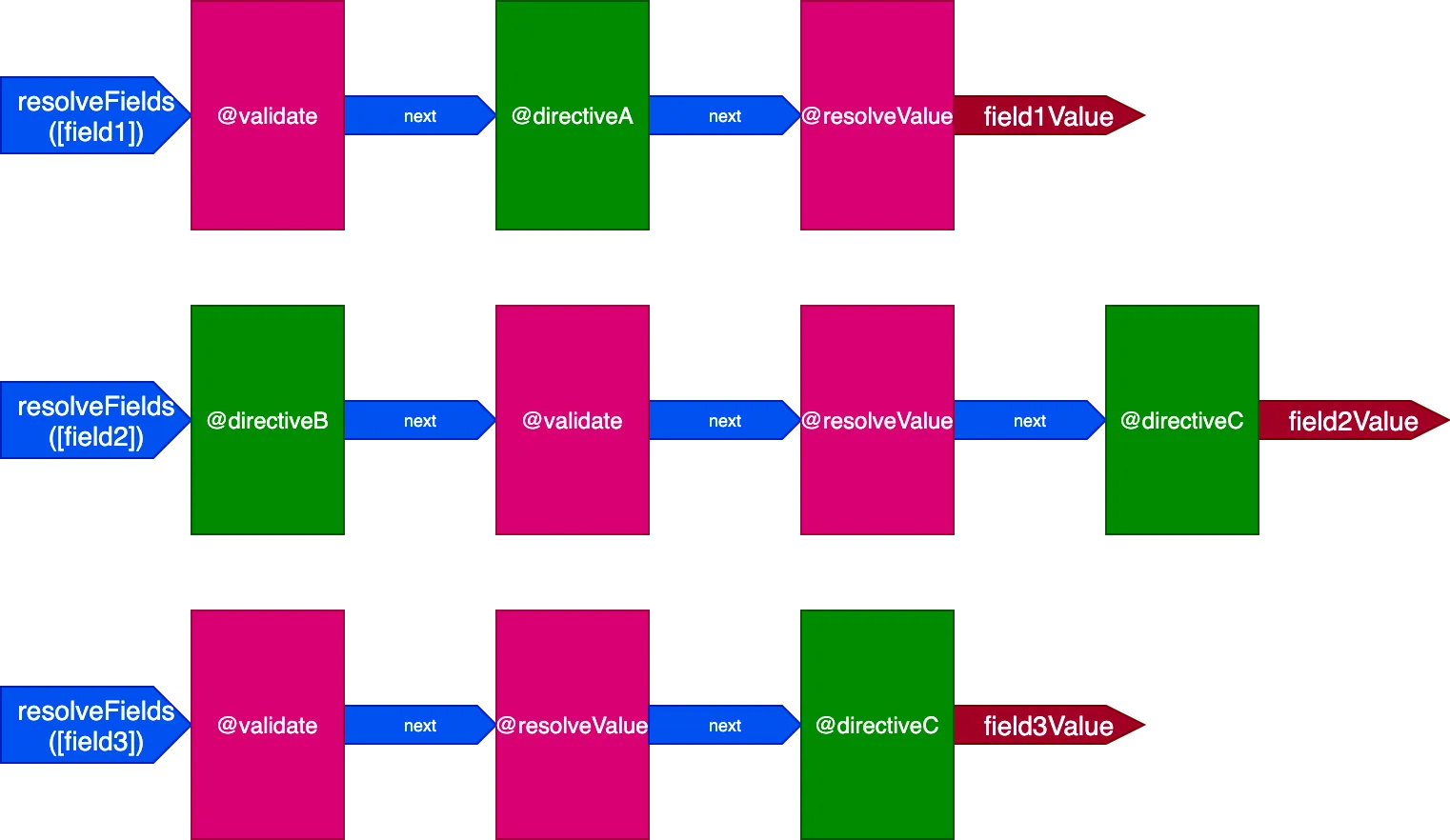
W tym przypadku, mimo że dyrektywy @validate i @resolveValueAndMerge są stosowane do 3 pól, ponieważ są wykonywane przez 3 różne potoki dyrektyw, będą wykonywane niezależnie od siebie, co prowadzi nas z powrotem do sytuacji, w której dyrektywa jest wykonywana na jednym elemencie na raz.
Rozwiązaniem tego problemu jest unikanie tworzenia wielu potoków i obsługiwanie jednego potoku dla wszystkich pól. W konsekwencji silnik nie przekazuje już pól jako wejście do potoku, ponieważ nie wszystkie dyrektywy z jednego potoku będą wchodzić w interakcję z tym samym zestawem pól; zamiast tego każda dyrektywa musi otrzymywać własną listę pól jako własne wejście.
Zatem dla tej query:
query {
field1 @directiveA
field2
field3
}...dyrektywy @validate i @resolveValueAndMerge otrzymają wszystkie 3 pola jako wejścia, a directiveA otrzyma tylko "field1":
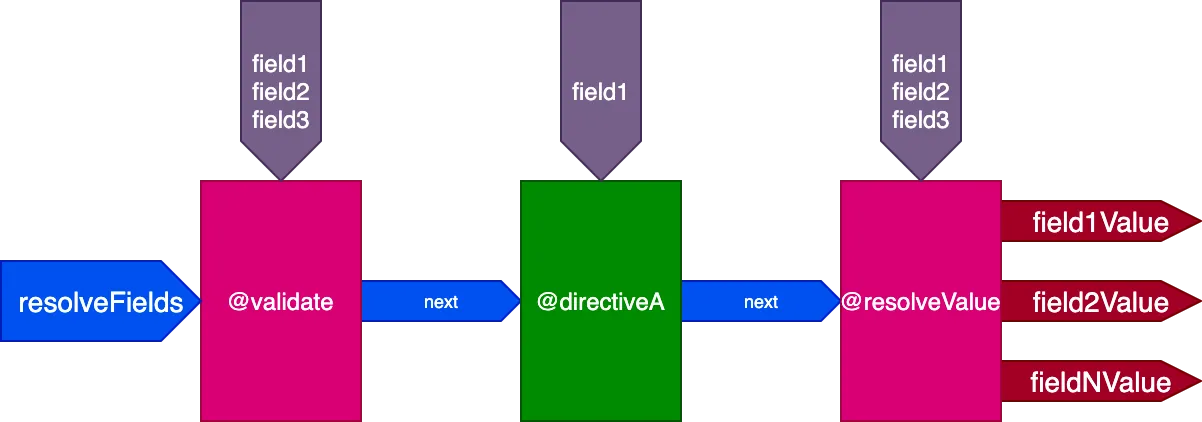
I dla tej query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...dyrektywy @validate i @resolveValueAndMerge otrzymają wszystkie 3 pola jako wejścia, directiveA otrzyma tylko "field1", directiveB otrzyma tylko "field2", a directiveC otrzyma "field2" i "field3":
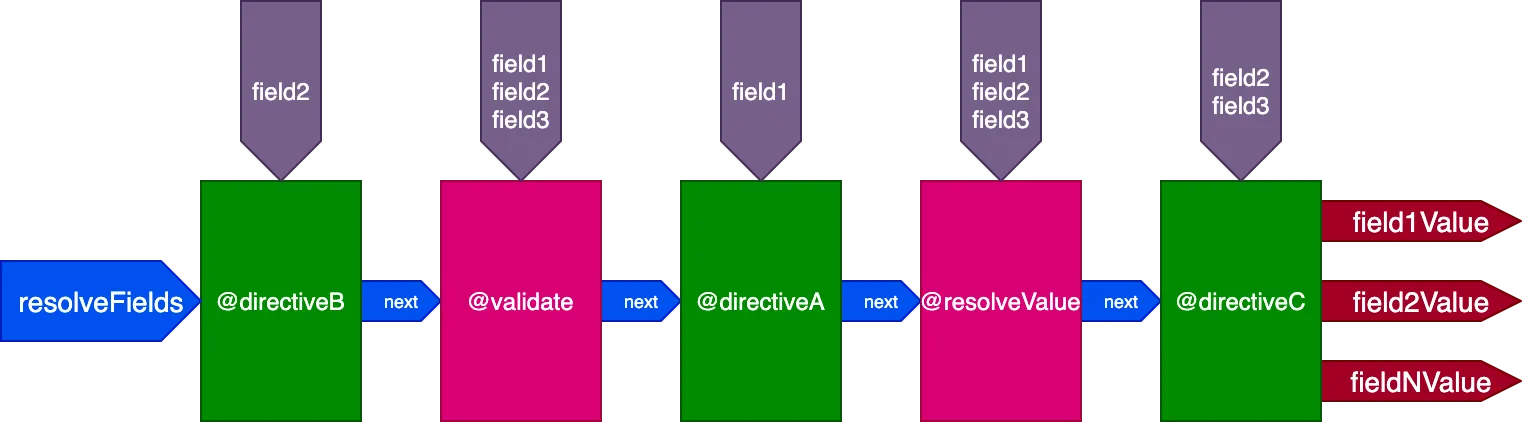
Kontrolowanie wykonania dyrektywy ID po ID
Do tej pory dyrektywa na pewnym etapie mogła wpływać na wykonanie dyrektyw na późniejszych etapach za pomocą flagi skipExecution. Jednak ta flaga nie jest wystarczająco szczegółowa dla wszystkich przypadków.
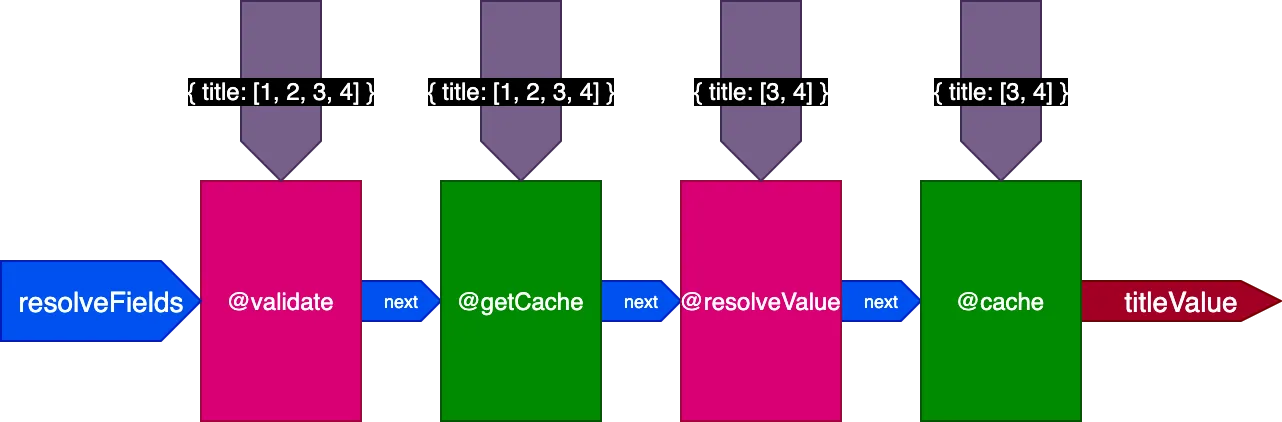
Na przykład rozważmy dyrektywę @cache, umieszczoną w slocie "end" w celu przechowywania wartości pola, tak aby następnym razem, gdy pole jest odpytywane, jego wartość mogła być pobrana z pamięci podręcznej za pomocą dyrektywy @getCache umieszczonej w slocie "middle":
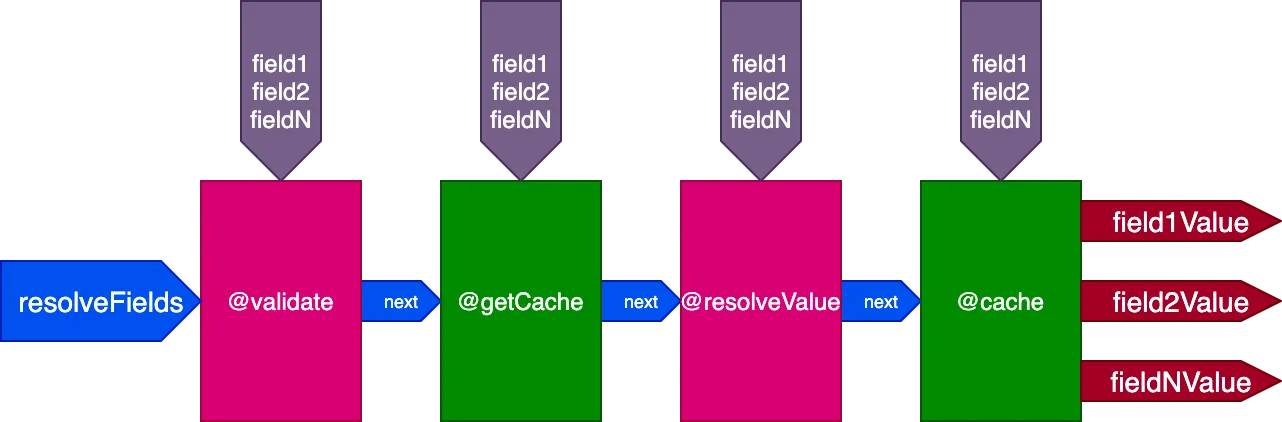
Podczas wykonywania tej query:
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}Serwer pobierze i zapisze w pamięci podręcznej 2 rekordy. Następnie wykonujemy tę samą query, ale zastosowaną do 4 rekordów:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}Podczas wykonywania tej 2. query 2 rekordy z 1. query były już w pamięci podręcznej, ale pozostałe 2 rekordy nie były. Jednak potrzebowalibyśmy, aby wszystkie 4 rekordy były już w pamięci podręcznej, żeby móc użyć flagi skipExecution. Lepiej byłoby, gdybyśmy mogli pobrać pierwsze 2 rekordy z pamięci podręcznej i rozwiązać tylko pozostałe 2 rekordy.
Dlatego ponownie aktualizujemy projekt potoku. Rezygnujemy z flagi skipExecution i zamiast tego przekazujemy każdej dyrektywie listę ID obiektów na pole, gdzie dyrektywa ma być zastosowana, za pomocą obiektu wejściowego fieldIDs:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}Zmienna fieldIDs jest unikalna dla każdej dyrektywy, a każda dyrektywa może modyfikować instancję fieldIDs dla wszystkich dyrektyw na późniejszych etapach. Zatem skipExecution może być wykonywane szczegółowo, ID po ID, po prostu usuwając ID z fieldIDs dla wszystkich nadchodzących dyrektyw w stosie.
Potok wygląda teraz tak:
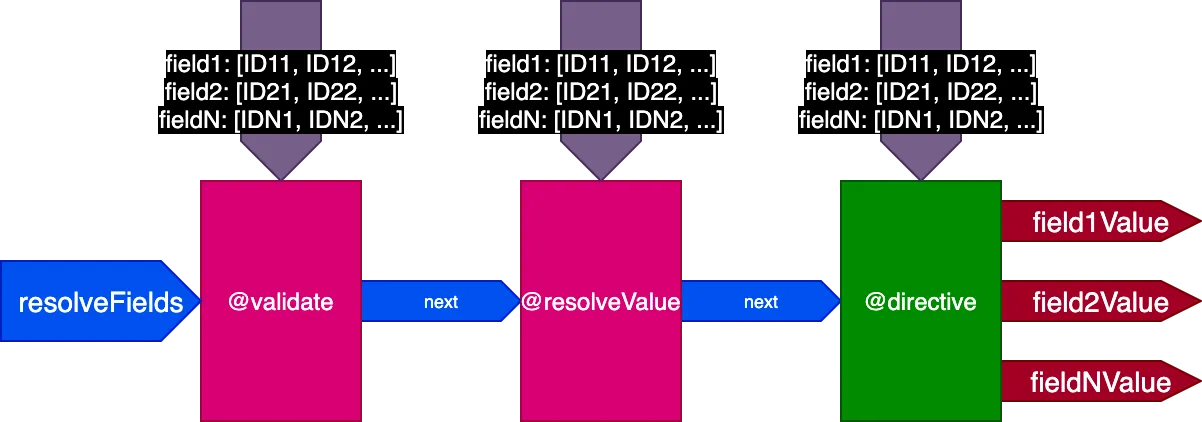
Zastosowane do poprzedniego przykładu, podczas wykonywania pierwszej query tłumaczącej 2 rekordy, potok wygląda tak:
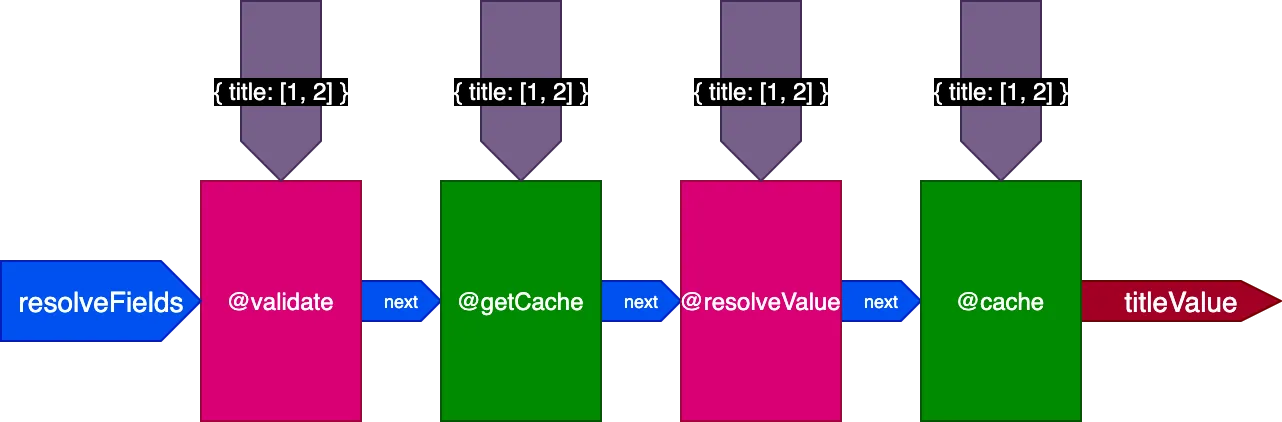
Podczas wykonywania drugiej query tłumaczącej 4 rekordy, dyrektywa @getCache otrzymuje ID wszystkich 4 rekordów, ale zarówno @resolveValueAndMerge, jak i @cache otrzymają tylko ID ostatnich 2 rekordów (które nie są w pamięci podręcznej):
Łącząc wszystko razem
To jest ostateczny projekt potoku dyrektyw:
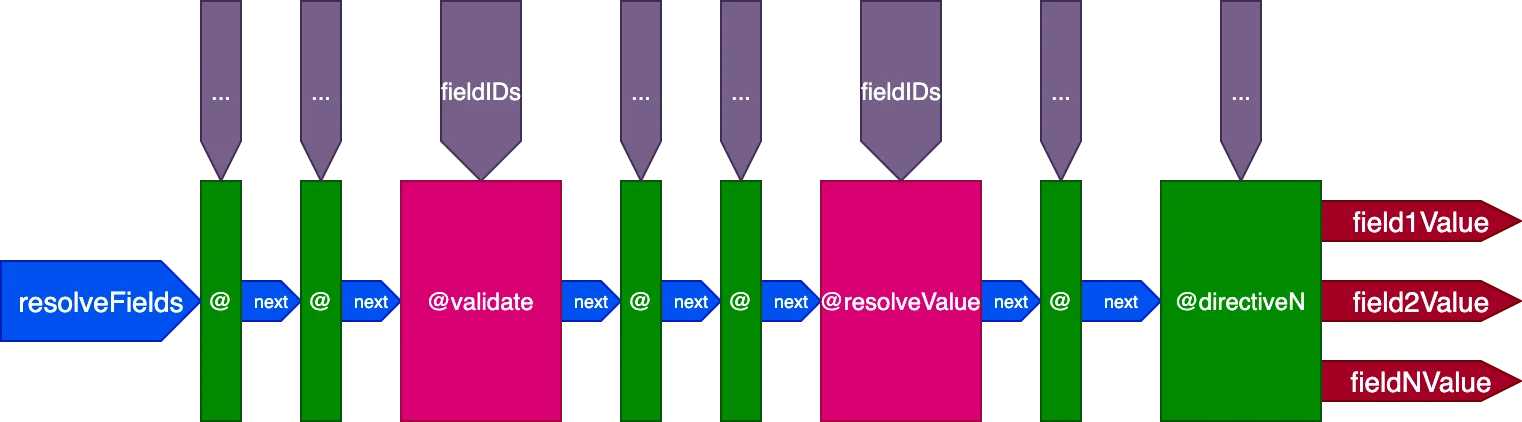
Podsumowując, oto jego cechy charakterystyczne:
- Resolvery pola są wywoływane z wnętrza potoku dyrektyw, za pomocą dyrektyw
@validatei@resolveValueAndMerge - Dyrektywy mogą być umieszczone w dowolnym z 5 slotów:
"beginning","before-validate","middle","after-validate"i"end" - Dyrektywy rozwiązują wiele pól w jednym wywołaniu
- Jeden potok zawiera wszystkie dyrektywy zaangażowane w query
- Każda dyrektywa otrzymuje własny zestaw ID do rozwiązania na pole za pomocą zmiennej
fieldIDs - Dyrektywy mogą modyfikować zmienną
fieldIDsdla wszystkich dyrektyw na późniejszym etapie potoku