
Manipulowanie kolejnością rozwiązywania pól
Celem dyrektywy @export dostarczanej przez Multiple Query Execution jest eksportowanie wartości pola (lub zestawu pól) do zmiennej, która zostanie użyta w innym miejscu w query.
Ta dyrektywa nie działałaby, gdyby odczyt zmiennej następował przed wyeksportowaniem wartości do zmiennej. Dlatego silnik musi zapewniać sposób kontrolowania kolejności wykonywania pól.
Gato GraphQL oferuje sposób manipulowania kolejnością wykonywania pól za pomocą samej query. Silnik ładuje dane iteracyjnie dla każdego typu — najpierw rozwiązuje wszystkie pola pierwszego napotkanego w query typu, potem wszystkie pola drugiego napotkanego typu i tak dalej, aż nie pozostanie żaden typ do przetworzenia.
Na przykład poniższa query obejmująca obiekty typów Director, Film i Actor:
{
directors {
name
films {
title
actors {
name
}
}
}
}...jest rozwiązywana przez silnik GraphQL w tej kolejności:

Jeśli po przetworzeniu typ zostanie ponownie odwołany w query w celu pobrania niepobranych danych (np. z dodatkowych obiektów lub dodatkowych pól już załadowanych obiektów), typ jest dodawany ponownie na końcu listy iteracji.
Na przykład, jeśli odpytamy również pole preferredDirector obiektu Actor (które zwraca obiekt typu Director) w taki sposób:
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...to silnik GraphQL przetwarza query w tej kolejności:

Zobaczmy, jak wygląda wykonanie @export w pojedynczej query. W pierwszej próbie tworzymy query tak jak zwykle, nie myśląc o kolejności wykonywania pól:
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}Po uruchomieniu query otrzymujemy taką odpowiedź:
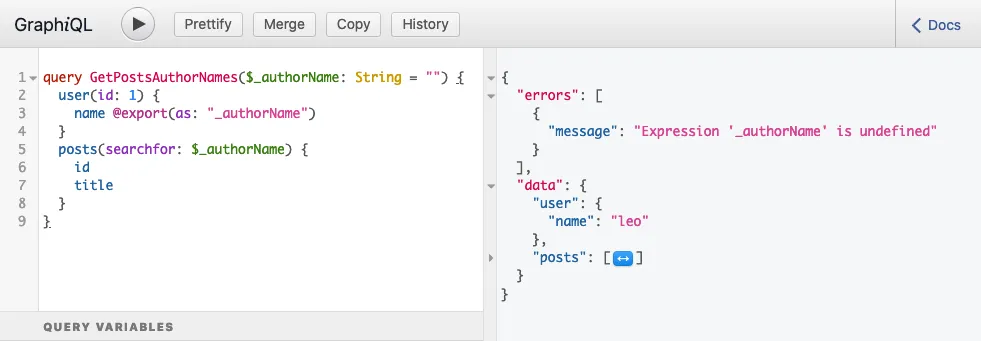
...która zawiera następujący błąd:
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}Ten błąd oznacza, że w momencie odczytu zmiennej $authorName nie była ona jeszcze ustawiona; miała wartość undefined.
Zobaczmy, dlaczego tak się dzieje. Najpierw analizujemy, jakie typy pojawiają się w query — dodane jako komentarze poniżej:
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}Aby przetworzyć typy i załadować ich dane, silnik ładowania danych dodaje typ query Root do listy FIFO (First-In, First-Out, „pierwszy wchodzi, pierwszy wychodzi"), czyniąc [Root] listą początkową przekazywaną do algorytmu, a następnie iteruje po typach sekwencyjnie w taki sposób:
| # | Operacja | Lista |
|---|---|---|
| 0 | Przygotowanie listy FIFO | [Root] |
| 1a | Usunięcie pierwszego typu z listy (Root) | [] |
| 1b | Przetworzenie wszystkich pól odpytanych z typu Root:→ user(by: {id: 1})→ posts(filter: { search: $authorName })Dodanie ich typów ( User i Post) do listy | [User, Post] |
| 2a | Usunięcie pierwszego typu z listy (User) | [Post] |
| 2b | Przetworzenie pola odpytanego z typu User:→ name @export(as: "authorName")Ponieważ jest to typ skalarny ( String), nie ma potrzeby dodawania go do listy | [Post] |
| 3a | Usunięcie pierwszego typu z listy (Post) | [] |
| 3b | Przetworzenie wszystkich pól odpytanych z typu Post:→ id→ titlePonieważ są to typy skalarne ( ID i String), nie ma potrzeby dodawania ich do listy | [] |
| 4 | Lista jest pusta, iteracja kończy się. |
Tutaj widać problem: @export jest wykonywany w kroku 2b, ale był odczytywany w kroku 1b.
Tu właśnie musimy kontrolować przepływ wykonywania pól. Zaimplementowane rozwiązanie polega na opóźnieniu momentu odczytu wyeksportowanej zmiennej, osiągniętym przez sztuczne odpytanie pola self z typu Root.
Pole self, jak wskazuje jego nazwa, zwraca ten sam obiekt; zastosowane do obiektu Root zwraca ten sam obiekt Root. Można zapytać: „skoro już mam obiekt główny, po co miałbym go pobierać ponownie?". Dlatego że algorytm silnika będzie musiał dodać to nowe odwołanie do Root na końcu listy FIFO, a my możemy celowo rozmieszczać odpytywane pola przed każdą z tych iteracji lub po niej.
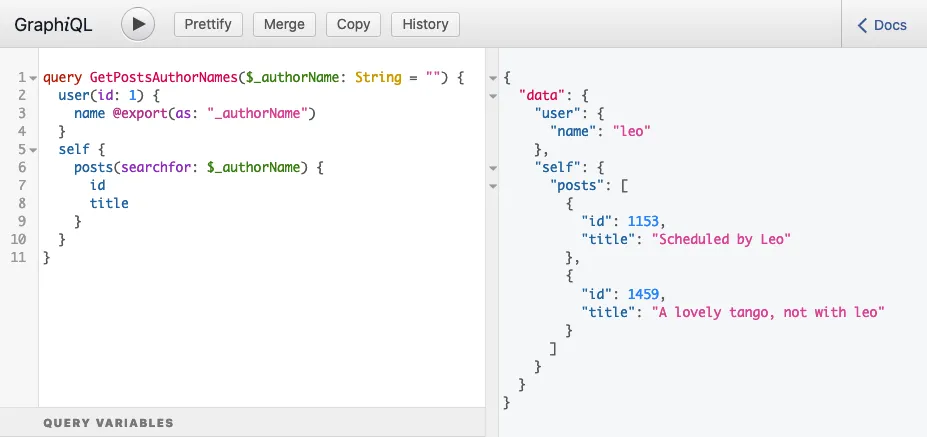
Dlatego pole posts(filter:{ search: $authorName }) jest umieszczone wewnątrz pola self w powyższej query, a jej uruchomienie daje oczekiwaną odpowiedź:
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
Prześledźmy kolejność przetwarzania typów w tej query, aby zrozumieć, dlaczego działa ona poprawnie:
| # | Operacja | Lista |
|---|---|---|
| 0 | Przygotowanie listy FIFO | [Root] |
| 1a | Usunięcie pierwszego typu z listy (Root) | [] |
| 1b | Przetworzenie wszystkich pól odpytanych z typu Root:→ user(by: {id: 1})→ selfDodanie ich typów ( User i Root) do listy | [User, Root] |
| 2a | Usunięcie pierwszego typu z listy (User) | [Root] |
| 2b | Przetworzenie pola odpytanego z typu User:→ name @export(as: "authorName")Ponieważ jest to typ skalarny ( String), nie ma potrzeby dodawania go do listy | [Root] |
| 3a | Usunięcie pierwszego typu z listy (Root) | [] |
| 3b | Przetworzenie pola odpytanego z typu Root:→ posts(filter:{ search: $authorName })Dodanie jego typu ( Post) do listy | [Post] |
| 4a | Usunięcie pierwszego typu z listy (Post) | [] |
| 4b | Przetworzenie wszystkich pól odpytanych z typu Post:→ id→ titlePonieważ są to typy skalarne ( ID i String), nie ma potrzeby dodawania ich do listy | [] |
| 5 | Lista jest pusta, iteracja kończy się. |
Teraz widać, że problem został rozwiązany: @export jest wykonywany w kroku 2b, a odczytywany w kroku 3b.
Multiple Query Execution robi dokładnie to podczas oddzielania queries: konwertuje dokument GraphQL, dodając pola self, tak aby pola każdej operacji były wykonywane dopiero po rozwiązaniu wszystkich pól ze wszystkich poprzednich operacji.